Proton nomenclature for proteins and nucleic acids
|

|
|
|
|
|
Based on IUPAC rules for polypeptides (ref. 1) and nucleic acids
(ref. 2) and later recommendations (ref. 3) as implemented in WHAT (ref.
4) in a 1999 study (ref. 5).
Example files in a kind of PDB format
|
|
|
|
Notes:
-
These PDB files do not adhere to the PDB format guidelines but are provided
in the hope that most software can deal with the information nevertheless.
Moreover, atom names follow the IUPAC guidelines instead of the PDB nomenclature.
The atom names are left aligned unlike the PDB format
guidelines.
This is not an issue in STAR files like mmCIF and NMR-STAR but programs
reading PDB might not work because they expect the alignment of the PDB
format.
-
No header information is included.
-
Please let me know if there is a nomenclature bug in these files with respect
to IUPAC rules or if the wording of this text could be improved.
The computer representation for ' is a single quote and for '' is two
single quote symbols.
Amino Acid Details:
-
The N-terminal protons on a N-terminal proline are labelled H2 (pro-R)
and H3 (as in residue 1 in file aa_weirdos_XX.pdb).
-
If the protonation state of an arginine side chain is know to be uncharged
(as in residue 2 in file aa_weirdos_XX.pdb),
the eta nitrogen (NH) with only one proton will be numbered 1. This is
documented in table II of ref. 1 as the alternative state. This overrules
the distinction made on the basis of cis/trans that is applicable
otherwise. The proton on NH1 will be labelled according to its cis/trans
position.
-
C-terminal oxygens are labelled O' and O'' (as in the last residue in file
aa_weirdos_XX.pdb).
If a proton is present on one of the oxygens, then this proton will be
labelled O'' because of it's lower priority in the CIP rules due to the
single bond instead of a double bond between C and O'. If no proton is
present, the oxygen atoms are labelled according to their cis/trans position
with O' being mostly cis with respect to N. These rules are detailed in
ref 1. Note that no distinction is based on a difference in the bond lengths
of the C-O' and C-O'' (Gert, is this last statement also correct in WHAT
IF). Similar rules apply for the sidechain oxygen atoms in aspartate and
glutamate.
-
If one or two protons are missing in a methyl or amino group (e.g. NH3
group in lysine of file aa_weirdos_XX.pdb)
the protons will be numbered starting from 1. This is somewhat opposite
of the situation in arginine's planar group detailed above.
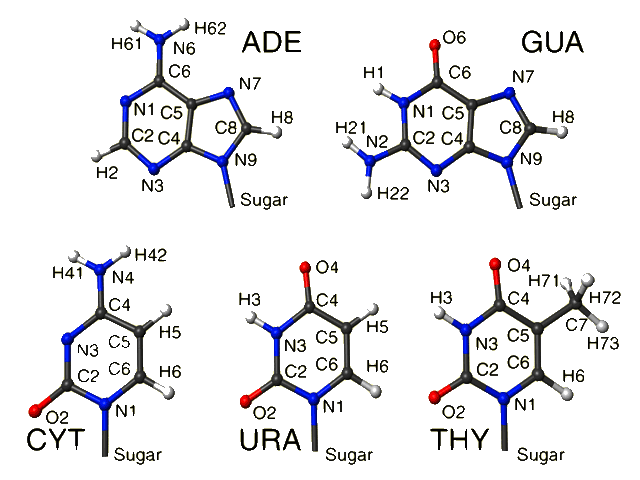
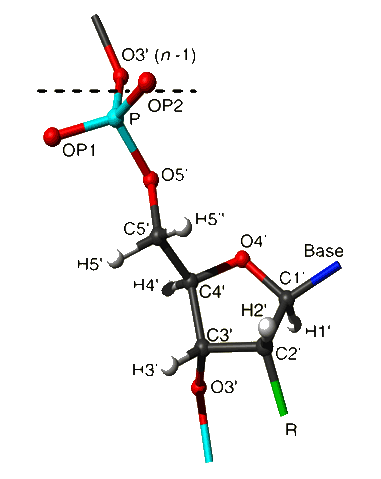
Nucleic Acid Details:
|
-
In case of deoxyribose R equals H2'', in case of ribose R equals O2' -
HO2'.
-
The dashed line shows the nucleotide boundary.
-
The methyl group in thymine (nucleotide 4 in file dna.pdb)
is numbered by assuming higher priority for C4 than for C6. So H71 is the
hydrogen with the smallest (positive or negative) angle with respect to
C4. C4 is chosen as having the higher priority because of the common numbering
within the base. C4 also has a higher priority in CIP rules. The reason
I mention this case is because C6 is closer to the nucleic acid 'backbone',
and if protein rules assigning priority to backbone and side chain atoms
were applied a different outcome would be the result.
-
The phosphorus-bound oxygens OP1 and OP2 are labelled in accordance with
ref 3 (OP1 is pro-S) in agreement with the IUPAC recommendations
(ref 7) and ref 6 but in contrast to the statement in ref 3.
|
|
|
References:
-
IUPAC-IUB. (1970). Abbreviations and symbols for the description of the
conformation of polypeptide chains. Tentative rules (1969). IUPAC-IUB Commission
on Biochemical Nomenclature. Biochemistry 9, 3471-3479.
-
IUPAC-IUB. (1983). Abbreviations and symbols for the description of conformations
of polynucleotide chains. Recommendations 1982. IUPAC-IUB Joint Commission
on Biochemical Nomenclature (JCBN). Eur. J. Biochem.
131,
9-15.
-
Markley, J.L., Bax, A., Arata, Y., Hilbers, C.W., Kaptein, R., Sykes, B.D.,
Wright, P.E. and Wüthrich, K. (1998). Recommendations for the presentation
of NMR structures of proteins and nucleic acids. J. Biomol. NMR 12,
1-23.
-
Vriend, G. (1990). WHAT IF: a molecular modeling and drug design program.
J. Mol. Graph. 8, 52-56.
-
Doreleijers JF, Vriend G, Raves ML, and Kaptein R. "Validation of NMR structures
of proteins and nucleic acids: Proton geometry and nomenclature" Proteins:
Struct. Funct. & Genetics. (1999) 37, 404-416.
-
Feigon, J. and Schultze, P. (1997). Chirality errors in nucleic acid structures.
Nature 387, 668-668.
-
Liebecq, C. Biochemical Nomenclature and Related Document (Portland,
London, 1992).
Contact the author for
information or comments.
|